차집합 구하기, 어떤 쿼리가 좋을까?
| 김정선(jskim@feelanet.com) 필라넷 DB사업부 수석컨설턴트 SQLServer 아카데미/트라이콤 교육센터 강사 Microsoft SQL Server MVP |
|
차집합(Difference of Sets) 두 집합 A, B를 생각할 때, A에 속하고 B에는 속하지 않는 원소로 구성된 집합을 A에 대한 B의 차집합이라하고, A-B로 표시하며 흔히 벤 다이어그램으로 나타낸다. |
이번에 좀 쉬운 내용으로 정했습니다 ^^
차집합을 구하라
“주문이 없는 제품을 구하라!”,
“거래가 없는 고객을 구하라!”,
“미발송된 주문 상세 내역을 구하라!”
차집합과 유사한 성격의 결과 집합을 도출하는 쿼리를 가끔 작성하게 됩니다. 이 때, 가장 큰 문제 중의 하나는 바로 쿼리 성능 문제입니다. 수행되는 집합 연산의 성격 상 모델 변경 없이 쿼리 만으로 좋은 성능을 만들기란 쉽지가 않습니다. 대량 범위의 데이터에서는 더 큰 문제를 내포하게 됩니다. 그런데, 현장에서 만들어진 쿼리를 보면 LEFT OUTER 조인과 같은 가장 나쁜 쿼리 유형을 선택해서 사용하고 있는 것을 자주 보게 됩니다. SQL Server 관련 Q/A에서도 많이 볼 수 있는 질문 유형 중의 하나였습니다.
언젠가는 한 번 비교를 해 보고 그 결과를 많은 개발자 혹은 DBA들과 공유하자 마음 먹고 있었습니다. 또한 다른 분들의 좋은 솔루션이나 의견도 듣고 싶었습니다. 얼마 전 SQL 전문 Blog에 관련된 글이 올라온 것을 보고 그 기억을 되살리게 되었고, 이제서야 잠깐 짬을 내 기본적인 쿼리 유형들을 샘플로 간단히 만들고 이를 비교한 내용들을 기록합니다. 특히, SQL Server 2005의 Query Optimizer에서 이전 버전과 두드러진 한 가지 차이점을 공통적으로 보이고 있어서 재미 있는 이슈가 될 듯 합니다. 이 또한 예제에 포함시켜 두었습니다.
간단한 예제들이지만, 차집합 성격의 결과 집합 도출 시 어떤 쿼리 유형들이 가능할지 그 선택 범위를 살펴보고 다양한 상황에 따라 적절한 접근 방법으로 활용하면 도움이 될 것이라 판단됩니다. 특히, 막연히 LEFT OUTER 조인만을 사용했던 경험이 있다면 이를 개선할 수 있는 다른 접근 방법들을 살펴볼 수 있을 겁니다.
쿼리 유형별 예제
LEFT OUTER JOIN 방식을 포함해서 쉽게 사용할 수 있는 몇 가지 예제 쿼리들을 다루고자 합니다. 각 유형별로 실행 계획과 I/O(실행 계획 이미지 하단에 포함)를 함께 표시하고 그 특징을 간단히 소개합니다. 설명을 통해 특징과 차이점을 알 수 있습니다. 특히, 몇 가지 쿼리에 대해서는 SQL Server 2000버전과의 큰 차이점을 하나 보여줍니다. 이 또한 정리해 두었습니다. 아래에서 살펴보시기 바랍니다.
1. NOT IN
2. NOT IN + 상관서브쿼리
3. NOT IN + 상관서브쿼리+ TOP 1
4. NOT EXISTS + 상관서브쿼리+ TOP 1
5. 상관 서브쿼리+ TOP 1 + IS NULL
6. OUTER JOIN + IS NULL
7. OUTER APPLY + IS NULL (SQL Server 2005 해당)
8. EXCEPT + (생략됨) 서브쿼리(혹은JOIN) (SQL Server 2005 해당)
참고. A, B 두 집합은 각각 Northwind의 Customers(91건), Orders(830건) 테이블로, 결과 집합은 주문(거래)이 없는 고객 집합을 도출하는 것을 예제로 합니다.

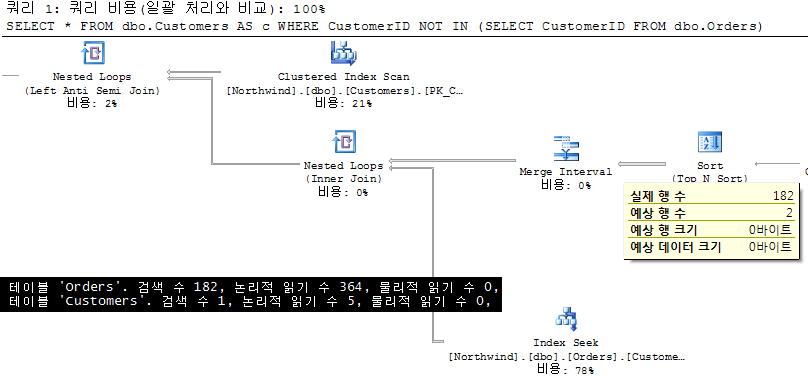

|
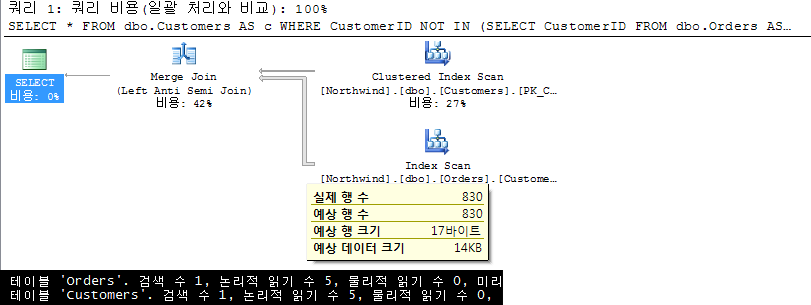
2. NOT IN + 상관 서브쿼리 |
|
서브 쿼리를 상관 서브쿼리로 변경, 쿼리 상에서 직접적으로 Orders테이블과의 조인 관계를 제한했다. 그 결과, 조인 연산자를 Nested Loop 조인으로 선택했을 때의 과도한 I/O를 해결하기 위한 대체 방안으로 Merge Join을 선택하고 있다. 한 번의 검색(1)으로 각 테이블을 액세스하고 그 결과를 Merge 물리적 연산자로 처리하며, 논리적으로는 차집합에 해당하는Anti Semi 조인으로 해결하고 있다. Merge 조인을 위해서는 조인 키에 Clustered Index나 Covering Index를 요구하는데 두 테이블이 각각 이를 만족하는 상황이므로, Query Optimizer가 손쉽게 Merge 조인을 선택할 수 있다. 빠른 응답 속도는 아니지만 결과론적으로 I/O는 최소화되었다. 그럼 좋아진 것일까? 문제는 Merge를 하기 위해서 Index Scan을 하느라 전체 데이터를 액세스하고 있다. 불필요한 데이터를 액세스하지 않는다는 기본 쿼리 작성 규칙에 위반되므로 좋다고도 볼 수는 없다. 따라서 Not bad! |
|
|
|
|
|
|

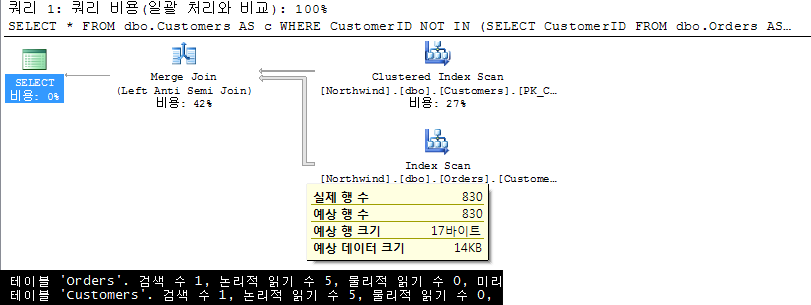
|
3. NOT IN + 상관서브쿼리+ TOP 1 |
|
저는 개인적으로 데이터 존재여부를 체크하는 서브 쿼리 유형에서 TOP 1 사용을 즐겨 합니다. 이는 교과서적인 내용이 전혀 아니지만, 컨설팅 경험을 통해서 인지하게 된 SQL Server Query Optimizer의 중요 특성 중의 하나입니다. 2번의 결과와 비교해 보면, 서브 쿼리 내 TOP 1을 추가한 것으로 쿼리 실행 계획의 큰 변화가 나타납니다. Query Optimizer가 Merge 조인 대신 Nested Loop 조인을 선택한 것입니다. 여기서 관심 있게 볼 부분은, 내부 입력인 Orders 테이블에 대해서는 Index Seek/Top/Filter 연산자의 순서입니다. 모든 검색 제한 조건을 처리한 후 Nested Loop 조인에 참여하고 있는 부분입니다. 이를 통해 반복적인 랜덤 I/O를 줄이게 됩니다. 이 방법은 실제로 김정선이 매우 즐겨 하는 서브쿼리 튜닝 전략 중의 하나입니다 ^^* 크게 2가지 목적을 달성하는 것입니다. 첫 번째는 조인 순서를 외부 쿼리에서 서브 쿼리로 풀리도록 강제하는 것이고, 두 번째는 Nested Loop 조인을 선택하도록 도와주는 것입니다. 이유는 Merge 조인과 같은 Stop-And-Go 방식의 연산자보다 Nested Loop 조인과 같은 Stream 방식이 훨씬 응답 속도(Response Time)가 빠르기 때문입니다. RDBMS는 일반적으로 OLTP성 쿼리로 주로 사용되며 OLTP는 쿼리 응답 속도가 제일 목표라는 사실 때문입니다. 상대적으로I/O가 커져 보이지만, 이는 실제로 필요한 만큼의 I/O임을 고려해야 합니다(앞서의 Merge 조인은 불필요한 전체 데이터를 액세스합니다) 따라서 제 의견은 (Very) Good |
|
|
|
|
|
|

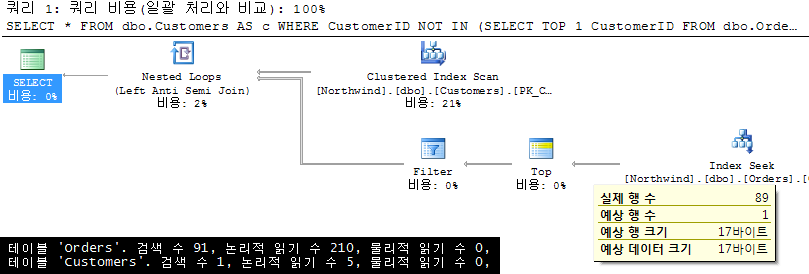
|
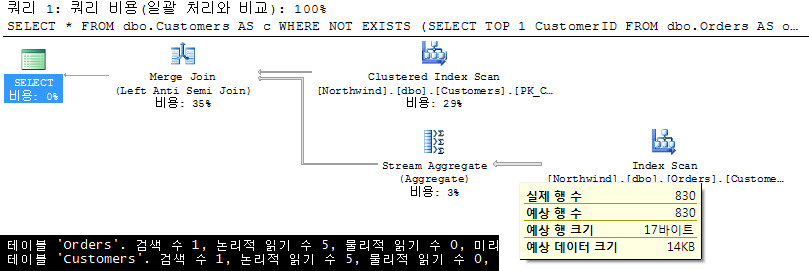
4. NOT EXISTS + 상관서브쿼리+ TOP 1 |
|
2번과 동일합니다. 다만IN이 아니라 EXISTS를 대신 사용했습니다. 여러분은 IN과 EXISTS중 어는 것을 선호하시나요? 아래 실행 결과를 보시면 2번과 유사하게 Merge Join으로 처리 됩니다. 그래도 전체 데이터를 조인으로 결합시키지 않고, Stream Aggregate 연산자를 이용해서 사실에 결합에 필요한 데이터(89건)만 처리하고 있다. 결국 2번보다는 개선된 계획. 그래도 역시 Not bad ^^ |
|
|
|
|
|
|

|
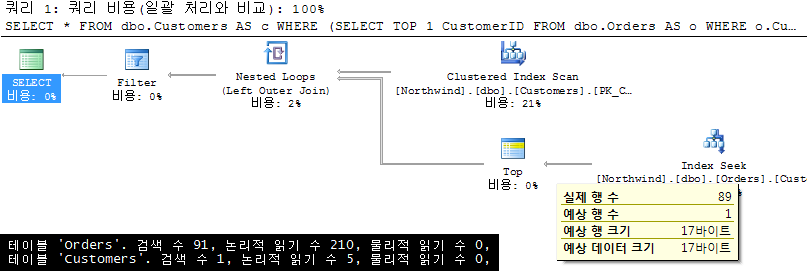
5. 상관 서브쿼리+ TOP 1 + IS NULL |
|
드디어 나와 군요. 위 3번과 함께 제가 가장 좋아하는 데이터 존재 여부 판단용 쿼리 유형입니다. 교과서에도 보기 힘든 쿼리 유형이죠. 실제로 모 고객사에서 쿼리 튜닝을 하면서 고객의 도움으로 우연찮게 발견한 방법입니다. 성능 이득이 너무나 대단해서 그 이후로 저의 필살기가 되었습니다. 헉^^; 그럼 김정선의 서브쿼리 튜닝 필살기를 여러분께 알려드린 거네요? 후후후, 이미 제가 진행하는 쿼리 튜닝 강의에서 알려 드리고 있습니다. 동일한 내용이므로 역시 (Very) Good! |
|
|
|
|
|
|

|
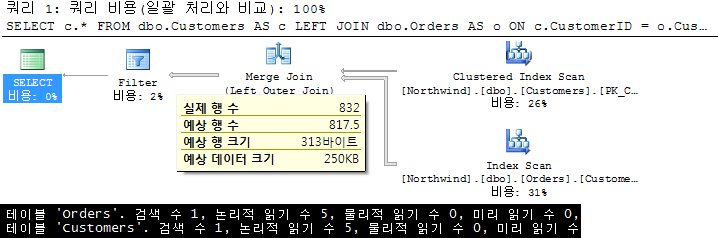
6. OUTER JOIN + IS NULL |
|
이제 나왔네요. OUTER JOIN이 가진 특성을 활용한 방법. 쿼리 자체는 흔하므로 설명 드리지 않아도 될 듯 합니다. 앞의 유형처럼 Merge 조인으로 처리되어 I/O는 작지만, 실행 계획을 보면 문제가 있음을 알 수 있습니다. 내부 입력의 조인 행 수에 대한 문제입니다. Orders 테이블에서 조인 조건을 만족하는 830건을 모두 OUTER 조인으로 결합하고 그 결과 832건을 도출한 뒤에 마지막 Filter 연산자에서 CustomerID IS NULL 조건으로 실제 행 수 2건을 만족하게 됩니다. 반드시 필요한 데이터만 액세스한다는 좋은 쿼리 작성의 기본 원칙에 위배가 되는 것입니다. 따라서 (Too) Bad! |
|
|
|
|
|
|

|
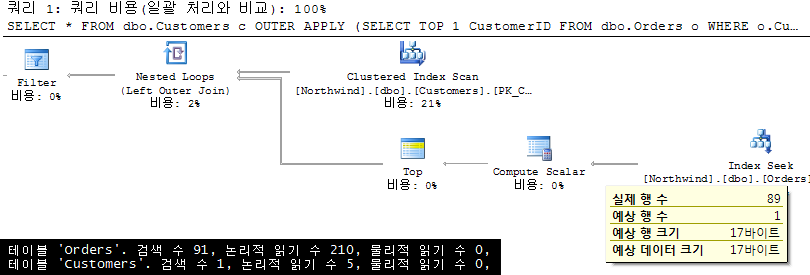
7. OUTER APPLY + IS NULL |
|
SQL Server 2005에 새로 도입된 OUTER APPLY 문을 적용한 예제입니다. 결과론적으로 앞서 3번 및 5번과 유사한 실행 계획과 I/O를 보여줍니다. 따라서 이 방법 또한 괜찮다는 것을 알 수 있습니다. Good! |
|
|
|
|
|
|

|
8. EXCEPT + (생략됨) 서브쿼리(혹은JOIN) |
|
수학적인 개념의 차집합(A-B)을 정확히 표현한 것이 바로 SQL Server 2005에 새로 도입된(ANSI 표준이죠 아마?) EXCEPT 문입니다. 아래 실행 계획에서 보듯이 EXCEPT를 사용한 결과는 EXISTS 연산자를 사용한 경우와 동일하게 처리됨을 알 수 있습니다. 그런데 한 가지 문제가 남았습니다. 아래 쿼리와 이전과 다르다는 것입니다. 차집합의 키 원소만을 처리하고 있고, 실제 결과 집합으로 필요한 Customer 테이블의 다른 칼럼 집합은 언급되지 않았다는 것입니다. 코드 주석에 언급했듯이 이 코드에 더해서 다시 조인이나 서브쿼리로 Customers 테이블의 나머지 칼럼을 처리해야 하므로, 결국 부가적인 I/O가 더해질 것입니다. 따라서, 성능은 Not Good! |
|
|
|
|
|
|

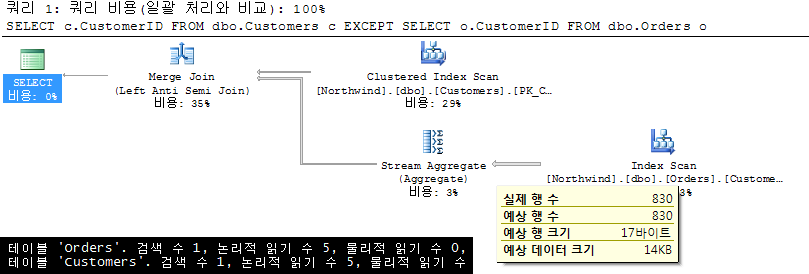
SQL Server 2000 vs. 2005, 누가 누가 잘하나?
지금까지 살펴본 예제 쿼리들에 대해서 SQL Server 2000과 비교했을 때 2005버전이 크게 달라진 부분이 하나 있습니다. 위 쿼리를 SQL Server 2000(SP3기반)에서 수행 시 가장 큰 차이는 바로 Mere 조인을 사용하지 않는다는 점입니다. 위 Merge조인 예제들이 모두 Nested Loop조인으로 처리됩니다. 그 중 2번) NOT IN + 상관서브쿼리 예제를 아래와 같이 비교해 보겠습니다.
|
SQL Server 2000버전) NOT IN + 상관 서브쿼리 |
|
Merge 조인을 사용해 I/O를 최소화했던 2005버전과 달리 2000 버전은 Nested Loop 조인을 사용해서 반복 I/O가 검색 행 수만큼 발생했습니다. 사실 상 앞서 우수하다고 판단했던 다른 유형의 쿼리들과 동일하게 처리되고 있습니다. Merge 조인을 위해 불필요한 데이터까지 액세스하지 않고 Index Seek를 통해 필요한 데이터만 제한적으로 검색하고 있습니다. 또한 앞서 언급한Nested Loop 조인의 응답 속도상의 이득도 취할 수 있습니다. |
|
|
|
|

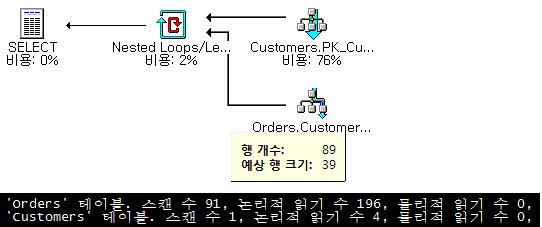
그럼, 이 두 가지를 비교했을 때 과연 어떤 실행 계획이 더 적합한 것일까? 물론 830건 밖에 되지 않는 성능을 논하기엔 매우 작은 테이블과 환경임을 감안하더라도 말입니다. 정답은 없겠지만 적어도 SQL Server 2005의 큰 변화 몇 가지는 확인할 수 있다는 점과 향후 쿼리 튜닝에 있어서 어떤 접근 방법을 우선 시 해야 할지에 대한 중요한 기준을 보여줍니다. 동일한 쿼리에 대해서 2000과 2005는 극명한 성능 차이를 보여줄 수 있다는 또 하나의 사례인 셈입니다.
철저한 I/O 이득을 우선으로 처리하고 있다는 느낌을 주는 2005의 Query Optimizer가 주는 느낌은 왠지 낯설기까지 합니다. 그 변화와 이득은 최대한 활용하되, 파생되는 문제점 또한 해결할 수 있는 다양한 접근 능력이 필요합니다.
결론
최종 판단은 여러분께 맡기겠습니다. 어떤 경우에 어떤 실행 계획이 적합하지 판단하실 수 있다면 그 유형에 맞게 선택해서 사용하시면 됩니다. 더불어 여기에 소개된 것은 기초적인 내용들입니다. 좀 더 복잡한 유형들이 존재합니다. 실제로 여러분들은 어떤 방법, 어떤 유형의 쿼리들을 사용하고 있는지요? 좋은 쿼리가 있으면 소개해 주세요. 많은 분들께 도움이 되실 것이라 믿습니다!
또한 위 쿼리 예제들에 대한 여러분들의 의견도 궁금합니다.
편하게 의견 주세요~~~
[출처] 차집합 구하기, 어떤 쿼리가 좋을까?|작성자 김정선